Computer Vision(CV) — Ultimate Beginners Guide to Know How Machines Interpret the Visual World?

If I asked you to name the objects in the picture below, you would probably come up with a list of words such as “pen, pencil, paper, laptop, mouse, table…” without thinking twice. Now, if I told you to describe the picture below, you would probably say, “It’s a picture of two people discussing office work” again without giving it a second thought.

Those are two extremely simple assignments that any individual with less than ideal insight or more at the age of six or seven could achieve. Be that as it may, behind the scenes, an exceptionally complicated interaction happens. Human vision is an extremely intricate piece of natural innovation that includes our eyes and visual cortex, yet it addition considers our psychological models of items, our theoretical comprehension of ideas, and our own encounters through billions and trillions of connections we’ve made with the world in our lives.
For a long time, individuals longed for making machines with the attributes of human insight, those that can think and behave like people. Quite possibly the most entrancing thought was to enable computers to “see” and decipher their general surroundings. The fiction of yesterday has become the reality of today.
The computer vision market is expected to reach $48.6 billion by 2022, making it an extremely promising UX technology
Today, Computer vision is one of the most sizzling subfields of man-made brainpower and AI, given its wide assortment of uses and enormous potential.
In this article, you’ll find out about some fundamental ideas of computer vision and how it’s utilized in reality and offer a couple of amazing models where this innovation can be applied in our lives. It’s a clear evaluation, for any individual who has ever thought about computer vision and yet isn’t actually sure what everything’s about and how it’s applied.
What is Computer Vision?
Computer vision is a field of artificial intelligence that deals with the science of making computers or machines visually enabled. The idea of computer vision depends on encouraging machines to deal with a picture so that they gain a high-level understanding from digital images or videos. Actually, machines endeavor to recover visual data, handle it, and decipher results through cutting-edge technology. On account of advances in man-made brainpower and developments in deep learning and neural network, the field has had the option to take incredible jumps as of late it has had the option to outperform people in certain errands related to detecting and labeling objects.
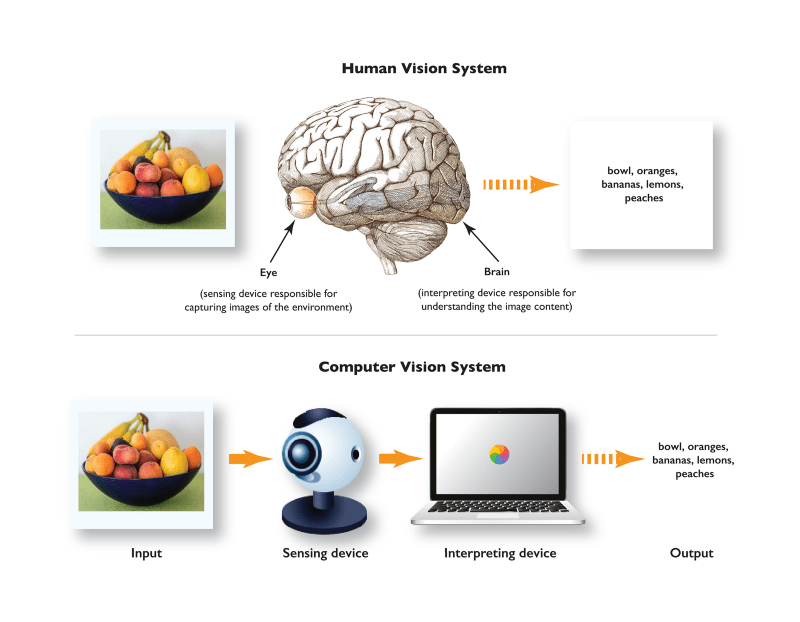
The Evolution of Computer Vision
1950’s
- IBM’s magnetic data-storage systems.
- Frank Rosenblatt’s Perceptron.
1960’s
- Development of 3D information about solid objects from 2D photographs of line drawings.
- MIT AI lab begins computer vision projects.
1970’s
- Introduction of AGM-65 Maverick optical contrast seeker missiles with onboard cameras for targeting.
- Optical Character Recognition (OCR) debuts via Kurzweil Computer Products.
1980’s
- Smart cameras, such as the Xerox optical mouse, and layered image processing.
2000’s
- Viola-Jones object detection framework (facial recognition and object detection).
- Pascal VOC Project was launched for developing image datasets for training.
2005
- Security Show Japan 2005 and the first mobile phone with working facial recognition features.
2010
- AI’s average object-recognition error rate becomes better than humans’; 2.5% versus 5%.
- First ImageNet competition. Developers competed to develop image recognition models. ImageNet now has up to 15 million images in 20,000 categories.
2012
- Google’s X Lab’s neural network starts to look for cat videos when allowed access to YouTube.
2014
- Tesla releases autopilot in its Tesla Model S electric car. The autopilot not only worked offline but offered advanced capabilities including parking and semi-autonomous driving.
2015
- Google introduces FaceNet for facial recognition. Requires minimum data set.
2016
- Niantic Inc. released Pokemon Go, an AR-based mobile game that relied on mobile cameras to display Pokemon in augmented reality. Players could globally battle them by traveling to certain physical locations and using their mobiles to “see” them through the in-app camera feature.
- Tesla releases Hardware Version 2 on its vehicles. A more advanced version that could automatically switch lanes, apply brakes, and manage acceleration and deceleration.
- Vision Processing Unit (VPU) microprocessors which are designed for machine vision processes started to trend.
2017
- ASOS integrates features that enable searching for products through photos from the client end.
2018
- Candy retailers Lolli & Pops deploy facial recognition in physical stores for identifying frequent customers as part of a reward program.
- Google announces its Google Maps Live View which provides live viewing of different sites using augmented reality on mobile cameras.
- NVIDIA announces that it will make its hyper-realistic face generator StyleGAN open source.
2019
- The UK high court allowed the utilization of automated facial recognition technology to look for individuals in the crowd.
How Does Computer Vision Work?
Before that, How do our brains subconsciously perform complex visual pattern recognition?
The human brain’s wired biological neural networks enable us, often intuitively, to make the best decisions possible with the information we’re given. biological neural networks are composed of approximately 10 billion neurons, each connected to about 10,000 other neurons.
Neural networks were inspired by a simplified model of a neuron. Neuron fires/activate based on specific conditions and patterns, this is a continuous process of passing the message along.
The goal of the ANN is not to mimic the human brain because at end of the day we don’t know enough about the deeper working of the brain. Our brains can see the difference between an image that contains a cat and an image that contains a dog. However, all a computer “sees” is a big matrix of numbers. The difference between how we perceive an image and how the image is represented is called the semantic gap.
Computer vision is all about identifying visual features and developing a visual vocabulary to talk about these images. Training DL models with thousands or millions of images, the machine learns the specific characteristics of objects.

Image Processing Vs Computer Vision

Image Processing is an activity that can play out a change on a picture, to get an upgraded picture, or to remove noise from the same. Here changes like blurring, resizing, smoothing, and so on are applied to the input picture, and as a result, the changed picture is returned.
In Computer vision, Image processing assists to extract characteristics/features associated with the image. Hence, Image Processing is a subset of the Computer vision field which assists with extricating undeniable features for object classification, object detection, etc

Challenges in Computer Vision
Viewpoint variation

Probably the greatest trouble of object detection is that an item seen from various viewpoints may look totally changed. For instance, the pictures of the cakes that you can see beneath contrast with one another in light of the fact that they show the item from various sides. Hence, the objective of indicators is to perceive objects from various perspectives.
Deformation
The subject of computer vision investigation isn’t just a strong object yet in addition bodies that can be disfigured and change their shapes, which gives extra intricacy to object detection.

Take a look at the pictures of football players in various stances. If the object detector is trained in just standing or running position, it will be unable to detect a player who is lying on the field or planning to make a move by bowing down.
Occlusion
In some cases, objects can be clouded by different things, which makes it hard to peruse the signs and recognize these items. For instance, in the below image, a cup is covered by the hand of the individual holding this cup.

In the subsequent picture, an individual is holding a cell phone so that the hands are blocking the object. Such circumstances make extra trouble for deciding the object.
Illumination Conditions
Lighting impacts the meaning of objects. Similar objects will appear to be unique relying upon the lighting conditions. Investigate the photos beneath: the less enlightened space, the less apparent the items are. These components influence the identifier’s capacity to characterize objects.

Cluttered or Textured Background
Objects that should be detected may mix away from plain sight, making it hard to recognize them. For instance, the below picture shows a ton of things, the area of which is befuddling when recognizing scissors or different things of interest. In such cases, the object detector might experience detection issues.

Scale Variation
This issue is quite common in image classification. Scale variation is actually having an image of the same object with multiple sizes. The image below is showing the scale variation of a similar item of that of a spoon, yet they are on the whole various sizes of spoons. Additionally, it’s anything but an obstruction i.e. a similar spoon may appear to be unique when it is shot very close versus when it is caught from a long way off.

Intra Class Variation
Intra-class variety in computer vision is showing the enhancement of chairs. From comfortable seats that we use to accomplish office work to seats that line our kitchen table, to current workmanship deco seats found in homes and our picture grouping algorithms should have the option to order this load of varieties effectively.

Here in the pictures above, we have various sorts of chairs. So our image classification framework ought to have the option to tackle the issue of intra-class variety.
Computer Vision Applications
Image Classification
Image Classification is a basic undertaking that endeavors to appreciate the whole picture overall. The objective is to group the picture by assigning it to a particular class. Regularly, Image Classification alludes to pictures in which just one item shows up and is classified.

Object Localization
Object Localization is the process of identifying objects in an image and indicating their location with a bounding box. An object proposal, on the other hand, is said to be apt if it accurately overlaps a human-labeled ground truth, a bounding box for the given object.
Object Detection
Object detection is a method that permits us to distinguish and find objects in a picture or video. With this sort of detection and localization, object detection can be utilized to include objects in a scene and decide and track their exact areas, all while precisely marking them. The cutting-edge strategies can be sorted into two principal types: one-stage detector and two-stage detector. One-stage strategies focus on inference velocity, and models incorporate YOLO, SSD, and RetinaNet. Two-stage strategies focus on recognition exactness, and model models incorporate Faster R-CNN, Mask R-CNN, and Cascade R-CNN.
Semantic and Instance Segmentation
Semantic segmentation, or image segmentation, is the task of bunching portions of a picture together which have a place with a similar object class. It’s anything but a type of pixel-level expectation on the grounds that every pixel in a picture is ordered by a class. Some benchmark datasets are Cityscapes, PASCAL VOC and ADE20K. Models are typically assessed with the Mean Intersection-Over-Union (Mean IoU) and Pixel Accuracy measurements.
Instance segmentation is the task of detecting and delineating each distinct object of interest appearing in an image.
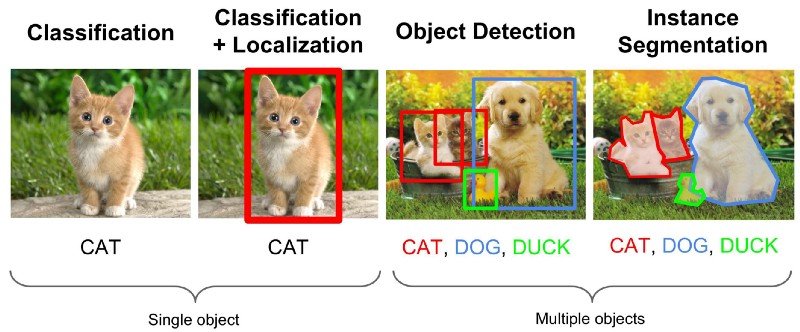
Instance segmentation is a challenging Computer vision task that requires the occurrences of objects and their per-pixel division mask.
Image Transformation Using GANs
Faceapp is an exceptionally fascinating and moving application among individuals. It’s anything but a picture control device and changes the information picture utilizing filters. Filters may incorporate maturing or the new gender swap filter. Take a glance at the below picture, clever right? A couple of months prior it was anything but a hotly debated issue on the web. Individuals were sharing pictures subsequent to trading their gender. Be that as it may, what is the innovation working behind such applications? Indeed, you got it accurately. It is Computer Vision, to be more explicit its Deep convolutional Generative adversarial networks. These are known as GAN is an energizing development in the field of computer vision. Despite the fact that GANs are an old idea, in the current structure, it was proposed by Ian Good individual in 2014. From that point forward it’s anything but a ton of improvements.

Human Pose Estimation
Human Pose Estimation is an intriguing utilization of Computer Vision. You probably might have heard about Posenet, which is an open-source model for Human posture assessment. In a nutshell, the present assessment is a computer vision algorithm to induce the posture of an individual or object present in the picture/video. Prior to examining the working of posture assessment let us initially comprehend ‘Human Pose Skeleton’. It is the arrangement of directions to characterize the posture of an individual. Further, present assessment is performed by recognizing, finding, and following the central issues of Humans’ present skeleton in an Image or video.

Creating a 3D Model From 2D Images
Here is another exceptionally intriguing utilization of computer vision. It changes over 2-dimensional pictures into 3D models. For example, imagine you have a photo from your old assortment and can change that into a 3d model and review it like you were there.

The specialists at DeepMind have concocted an AI framework that chips away at comparable lines. It is known as the Generative Query Network. It can see pictures from various points like people. Likewise, Nvidia has fostered an AI design that can foresee 3D properties from a picture. Essentially, Facebook AI is offering a comparable device known as the 3D Photo include.
Computer Vision Libraries
Open CV, Fast.ai, PyTorch, Keras, Tensorflow, Matlab, CUDA
Conclusion
Notwithstanding the new advancement, which has been amazing, we’re as yet off by a long shot to addressing computer vision. Computer vision is a mainstream point in articles about new technology. An alternate way to deal with utilizing information is the thing that makes this innovation unique. Huge measures of information that we make day by day, which a few groups consider as a curse of our age, are really utilized for our advantage — the information can encourage computers to see and get objects. This innovation likewise exhibits a significant advance that our development makes toward making man-made consciousness that will be just about as refined as people.
If you like what we do and want to know more about our community 👥 then please consider sharing, following, and joining it. It is completely FREE.
Also, don’t forget to show your love ❤️ by clapping 👏 for this article and let us know your views 💬 in the comment.
Join here: https://blogs.colearninglounge.com/join-us