What is Natural Language Processing (NLP)?


What is Natural Language Processing?
Analyzing and processing the Human Natural Language (Written & Spoken) to make the interaction between the computer & human or human & computer more seamless, meaningful, and interactive through a holistic study of computer science, linguistics, logic, and phycology are collectively called Natural language processing (NLP).
Evolution of Natural Language Processing
NLP has come a long way through many decades of struggle and improvements. Let’s have a quick go through the events that happened in the history of NLP.
- ‘Ferdinand de Saussure’ a swiss linguist and philosopher first led a foundation for linguistics and semiotics in the early 20th century. He argued that “meaning is created inside language, in the relations and differences between its parts”
- Later in 1950, Alan Turing showed us machines that could be part of a conversation through the use of a teleprinter.
- Noam Chomsky published his book, Syntactic Structures, in 1957. In it, he revolutionized previous linguistic concepts, concluding that for a computer to understand a language, the sentence structure would have to be changed.
- In 1964, the U.S. National Research Council (NRC) created the Automatic Language Processing Advisory Committee, or ALPAC, for short. This committee was tasked with evaluating the progress of Natural Language Processing research.
- In 1966, the NRC and ALPAC initiated the first AI and NLP stoppage, by halting the funding of research on Natural Language Processing and machine translation. “In 1966 Natural Language Processing and Artificial Intelligence was considered dead-end by many but not all”
- After a huge gap of 14 years in the year, the 1980s initiated a fundamental reorientation, with simple approximations replacing deep analysis, and the evaluation process becomes more rigorous.
After the year 2000, we observed huge development in the deep learning aspect, and feed-forward networks (NN) contributed a significant improvement to the evolution of NLP. Followed by deep learning evolution we saw an advancement of conversational devices like Alexa, Siri, etc through which NLP came into the common man’s home.
NLP today uses state-of-the-art models for language translation and understanding popularly known as Pre-trained Language Models(PLM) like BERT, ELMO, and GPT.
Let’s summarize the history in chronological order based on the major developments that happened in NLP.
1950 — George town Experiment
1970 — MicroWorlds, Ontology Extraction
1980 — Grammars, Statistical Models
2000 — Neural Language Models, Conditional Random Fields, Topic Models
2010 — Multitask Learning, Deep Learning, Word embeddings and Neural Networks for NLP
2018 — Sequence to Sequence Networks, Memory Based Networks, Pretrained Language Models
The future of NLP has endless possibilities. Human-Computer interaction should be like Human-Human interaction. The NLP community is working towards building applications that can copy Human Brains and merge with computers and so on.
Challenges in Natural Language Processing
Imagine a conversation between a kid and an Alexa device or a user interacting with a chatbot. The conversation between the user and the different devices happens through a complex cycle of taking inputs, processing them, understanding them, and responding back to the user in a very short span of time.
There are many aspects that bring a huge challenge in processing and understanding Human Language however primarily we can divide the challenges into the below categories:
Data Related Challenges:
Having the right amount of data in the right format for the right problem to be solved is nearly an impossible coincidence. We need to either crowdsource it or curate the available data according to the NLP problems we are solving.
Understanding Human Language can be so complex in terms of its variety, variation, native language influence, speech modulation, and so on. Languages are complex structures of rule-based formation that often are not followed. We, as humans, tend to break the rules which makes it more challenging to get the real context or meaning behind a sentence.
A classic example of the complexity of language could be (category of ambiguity issue)
“I saw a girl with a Telescope”
It’s tough to get the context whether I am talking about the girl having a telescope or I saw her with my telescope 🙂
As you see in the example above, data ambiguities add more challenges to the contextual understanding of the sentences which becomes a huge barrier in language processing tasks.
In NLP meaning comes from how a sentence formation happened, its semantics, context, and use of the right vocabulary and grammar. All of these aspects pose a real challenge for NLP. We see most of the data available in the real world NLP is unstructured, unbalanced, and heterogeneous which creates important to have correctly structured and formatted data to perform any NLP task.
Text Related Challenges:
We need Natural Language Processing as long as we are dealing with text. NLP problems could be in multi-class, multi-domain multi-language variations. For each input text, we see diversified data and each needs to have a different approach to solve a specific issue which again adds a greater challenge in processing the Human Language. However, the interesting part is every language understanding begins with understanding the grammar and parsing of sentences given as an input to the NLP Systems.
Noam Chomsky, an American linguist known as “the father of modern linguistics” worked on formal grammar in the late 1950s. He talked about the hierarchy of grammars (context-free grammar, context-sensitive grammar, finite state grammar ) and their linguistic complexity.
Low-Resource Languages
Large training data is the need for NLP model training as most of the NLP models require a large amount of training data. For many languages, there is not enough data to work on or simply there is no one interested in working on them.
Large or Multiple Document
Dealing with longer sentences, huge documents, and large corpora could become extremely tedious while using Recurrent Neural Network-based models as RNNs couldn’t hold the context well for longer sentences.
Though RNN’s successor algorithms such as LSTM, and Bi-LSTM have solved the problem of dealing with large sentences and they are holding their context to some extent.
As we go further in the Natural Language Processing domain it’s very clear that apart from processing the Human Natural Language understanding the whole language is a bigger challenge to look at. The issues like finding the meaning of a word or a word sense, determining scopes of quantifiers, finding referents of anaphora, the relation of modifiers to nouns, and identifying the meaning of tenses to temporal objects are still a problem to be solved. Besides, there remain challenges in pragmatics: a single phrase may be used to inform, to mislead about a fact or speaker’s belief about it, to draw attention, to remind, to command, etc.
Other challenges such as
Ambiguity
Example: A sentence “I saw a girl with a Telescope” is an ambiguous sentence due to its dual context.
There could be different levels of ambiguity (lexical ambiguity, syntax level ambiguity, etc) which we will discuss in our detailed article on NLU.
Synonymy
Similarly a word bank in the sentence ‘I went to the river bank for a walk’ and ‘He works as a bank manager’ can be synonyms when describing an object or a building but they are not interchangeable in all contexts.
Coreference
When we find all the contexts referring to one entity that’s present in a document or corpus is basically known as Coreference.
Personality, intention, emotions, and style
Depending on the personality of the author or the speaker, their intention and emotions can change. They might also use different styles to express the same idea which is extremely challenging to capture as data.
Components of NLP
NLP reads, NLU understands and NLG writes.
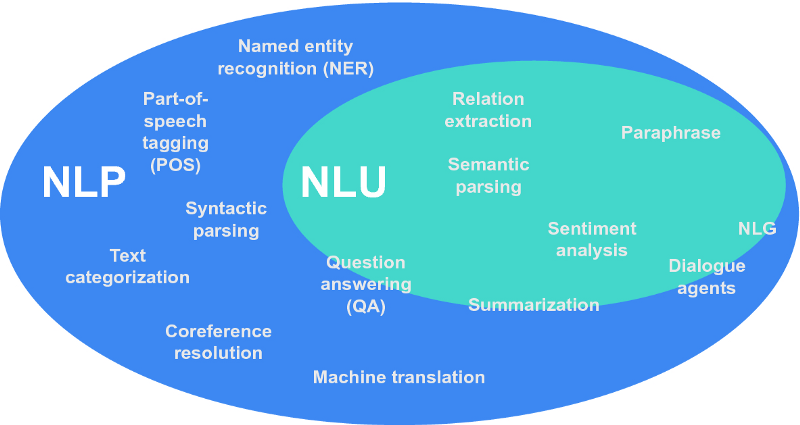
Based on the nature of the problem, requirement, and variations, NLP can be subdivided into primarily two segments and they are known as Natural Language Generation and Natural Language Understanding.
NLU
Natural Language Understanding (NLU), is the process of breaking down the human language into a machine-readable format. NLU uses grammatical rules and common syntax to understand the overall context and meaning of “natural language,” beyond literal definitions. Its goal is to understand written or spoken language the way a human would.
NLU is used in many modern NLP tasks like topic classification, language detection, and sentiment analysis, machine translation, and so on.
NLG
Natural Language Generation (NLG), is the process of generating natural language text from something else. In a broader sense, machine translation, which we discussed previously, is a text generation problem, because MT systems need to generate text in the target language.
An Example of Natural Language Generation can be Abstractive Text Summarization and Machine Reading Comprehension.
Applications of NLP

✅ Sentiment Analysis
This is one of the widely used applications of NLP and is used majorly in Social media and E-commerce platforms.
✅ Chatbots & Virtual Assistant
Virtually enabled conversations using Natural Language Processing are possible today using AI-Powered chatbots and Virtual Assistance.
Similar to Alexa, Siri is an example of a model of virtual Assistance used in Home appliances.

✅ Text Classification
Text classification (a.k.a. text categorization or text tagging) is the task of assigning a set of predefined categories to open-ended.
Text classifiers can be used to organize, structure, and categorize pretty much any kind of text — from documents, medical studies, and files, and all over the web. For example, new articles can be organized by topics; support tickets can be organized by urgency; chat conversations can be organized by language; brand mentions can be organized by sentiment; and so on.
✅ Text Extraction
Text extractors use AI to identify and extract relevant or notable pieces of information from within documents or online resources. Most simply, text extraction pulls important words from written texts and images.
Common uses of text extraction are:
- Keyword extraction (to identify the most relevant words in a text)
- Named entity extraction (to identify names of people, places, or businesses)
- Summary Extraction (to summarize a text)
- Text-from-image extraction, otherwise known as optical character recognition (OCR) (to lift text directly from an image, for example, PDFs)

✅ Machine Translation
Machine Translation is basically translating a text from one natural language (such as English) to another (such as Spanish).
Google Translator is an example of Machine Translation.

✅ Text Summarization
Extracting summaries from huge chunks of texts is basically known as Text Summarization.
Example: Summarizing the paragraph given as reading comprehension.

✅ Auto-Correct
Autocorrect or Spell check for short words is a useful and popular application of NLP. We could see Grammarly applications are evolving in this area.

✅ Speech Recognition
Speech is the most efficient, effective, and natural way of exchanging information among humans. Therefore if we can recognize the speech using a technological way, it will be profitable. That process that recognizes human speech is called Speech Recognition.

✅ Question-answering
Question Answering is a computer science discipline within the fields of information retrieval and natural language processing, which focuses on building systems that automatically answer questions posed by humans in a natural language.

✅ Grammar Checkers
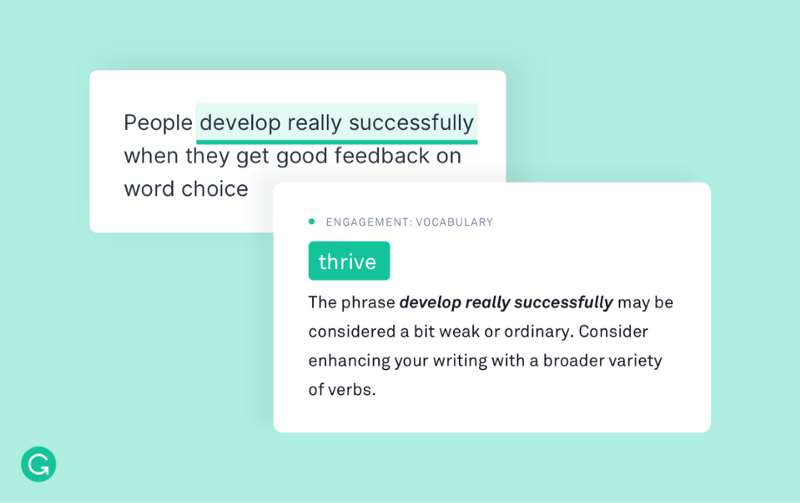
✅ Named Entity Recognition (NER)

✅ Part-of-Speech Tagging
POS tagging is the process of marking up a word in a corpus to a corresponding part of a speech tag, based on its context and definition.
grammatical tagging or word-category disambiguation is the process of marking up a word in a text (corpus) as corresponding to a particular part of speech, based on both its definition and its context — i.e., its relationship with adjacent and related words in a phrase, sentence, or paragraph. A simplified form of this is commonly taught to school-age children, in the identification of words as nouns, verbs, adjectives, adverbs, etc.
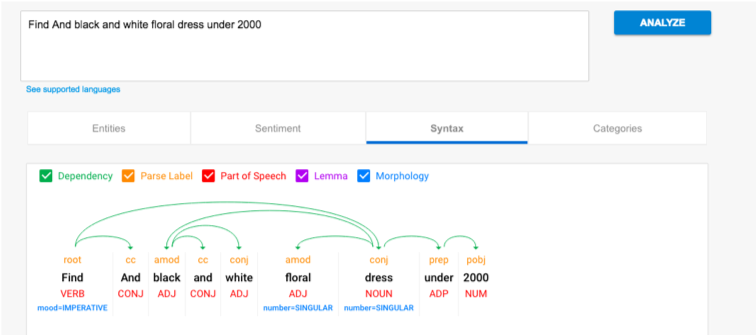
✅ Language Modeling
Language modeling is the art of determining the probability of a sequence of words.
This is useful in a large variety of areas including speech recognition, optical character recognition, handwriting recognition, machine translation, and spelling correction

✅ Machine Reading Comprehension
It is similar to the reading comprehension problem in our school exams.
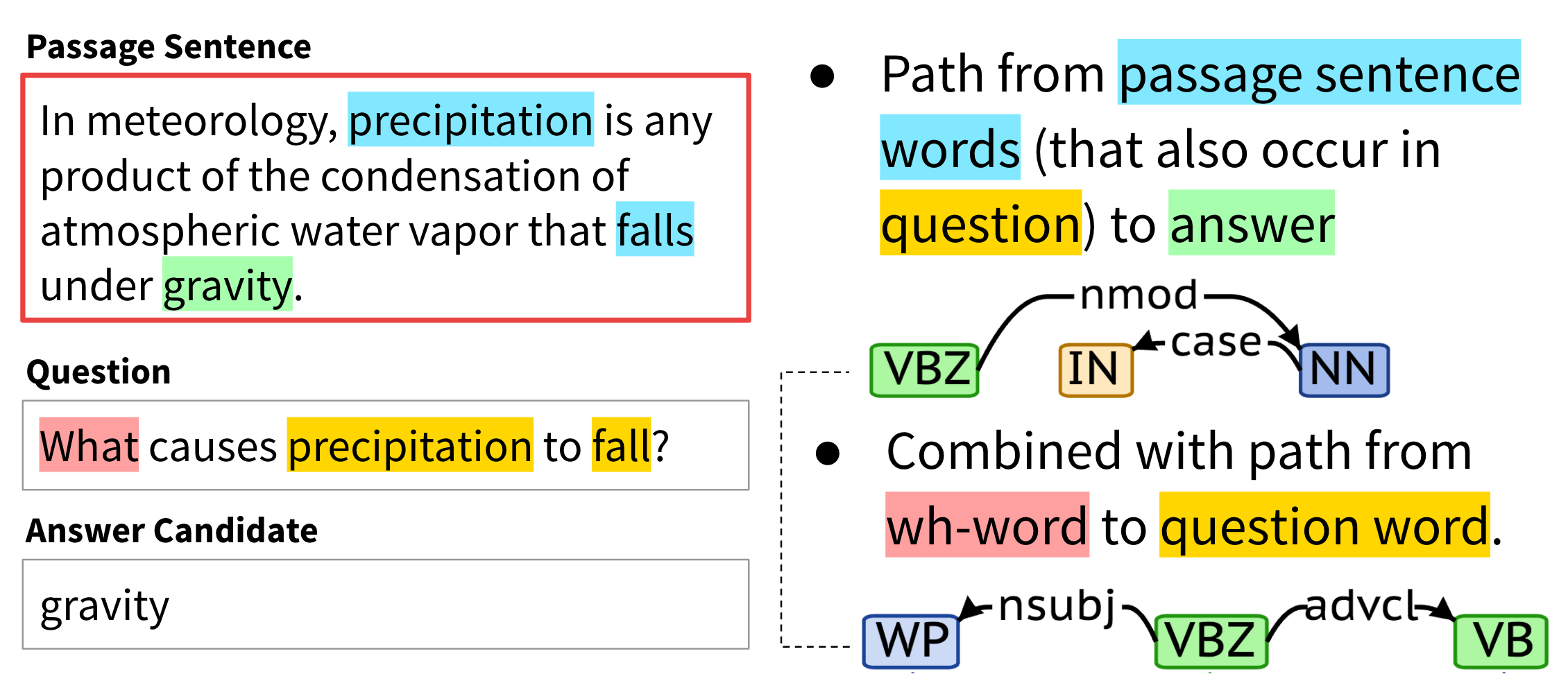
✅ Natural Language Generation(NLG)
Natural Language Generation, as defined by Artificial Intelligence: Natural Language Processing Fundamentals is the “process of producing meaningful phrases and sentences in the form of natural language.” In its essence, it automatically generates narratives that describe, summarize, or explain input structured data in a human-like manner at the speed of thousands of pages per second.
✅ Co-Reference Resolution
Coreference resolution is the task of finding all expressions that refer to the same entity in a text. It is an important step for hardcore NLP tasks that involve natural language understanding such as document summarization, question answering, and information extraction.
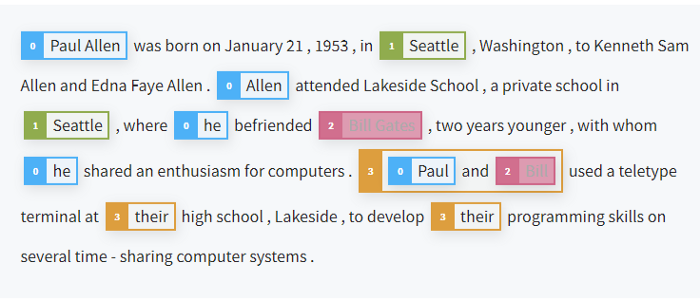
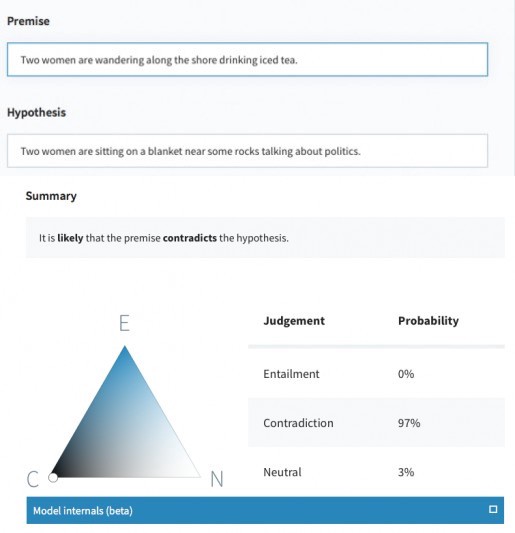
✅ Textual Entailment (TE)
Textual Entailment (TE) takes a pair of sentences and predicts whether the facts in the first necessarily imply the facts in the second one. Textual Entailment is a critical component of information extraction systems and is often used for filtering candidate answers by ensuring they entail a given extraction query.
NLP Heroes
List of Researchers and Innovators to follow.

Read the full article here.
NLP Libraries
Scikit-learn: It provides a wide range of algorithms for building machine learning models in Python.
Natural language Toolkit (NLTK): NLTK is a complete toolkit for all NLP techniques.
SpaCy: SpaCy is an open-source NLP library that is used for Data Extraction, Data Analysis, Sentiment Analysis, and Text Summarization.
Gensim: Gensim works with large datasets and processes data streams.
Hugging Face 🤗: It is an NLP-focused open-sourced library in particular around the Transformers.
TextBlob: It provides an easy interface to learn basic NLP tasks like sentiment analysis, noun phrase extraction, or pos-tagging.
If you like what we do and want to know more about our community 👥 then please consider sharing, following, and joining it. It is completely FREE.
Also, don’t forget to show your love ❤️ by clapping 👏 for this article and let us know your views 💬 in the comment.
Join here: https://blogs.colearninglounge.com/join-us