Understand Everything about ETL in Data Engineering- Extract, Transform, Load

Do you ever wonder how your organization gets all employee information, salary, and project details on a beautiful dashboard? Do you wonder how a Chef gets all his ratings and reviews consolidated as a single grade? Do you wonder how you will get a credit score based on all your credit history put together?
Of course, an amalgamation of math, business importance, science, decisions, etc. provides these results. But, the most important aspect in arriving at this is DATA. Without data, there would be no valid information.
We have obviously heard multiple blogs telling us that 50% of the world’s data is gathered in the last two or three years. So there is no scarcity of data. But, is only having data sufficient? Is data in its original form useful as is? Is dumping all the data in a single place enough to help us with business decisions or trends? Well, no!
What is ETL and how does it work?
Data has to undergo a process before it is deemed servable. For example, Gold!! Certainly, we cannot wear gold rocks as is. We will have to
- Extract gold particles from the rocks. It could be from a mine, or river, in any form.
- The extracted gold is melted, impurities are removed, and it is made to a standard approved format, i.e, Transform
- Finally, it can be made into(LOAD) a wedding ring or a WWE belt!
So moving gold(read it as data :P), between different parts of the system is called ETL.
Simply put, ETL is the process where data is extracted from various sources in its diverse forms, transformed to remove inconsistencies and improve data standard,& then loaded into a target place, from where clean data can be used to analyse, experiment,visualise and predict data.

Extract
Very few companies rely on one type of data or system. In most cases, data is managed from multiple sources and a variety of data analysis tools is used to generate business information. The most commonly used data sources are Databases(DB), Flat Files, Web Services, Other Sources such as RSS Feeds, etc. For such complex data strategies to work, data must be free to move between systems and applications.
In the first phase of the ETL process, structured and unstructured data is imported and integrated into a single repository. Raw data can be pulled from a spectrum of sources and moved to the staging area.
A staging area or landing zone is an intermediate storage area used for data processing during the extract, transform and load (ETL) process. The staging area is used to validate the extracted data before transferring it to the target system, database, or data warehouse.
Transform
After the successful extraction of data, it is moved to the next stage, transformation. To ensure the quality and accessibility of the data, and to facilitate efficient querying, data is transformed. This is one of the most important steps of the ETL process. The reason is, what we feed in is what we get out! If we feed in bad, incomplete data, it would result in bad insights, and incorrect analysis, and the whole use case boils down to a failure.
This step involves,
- Cleanup: Resolves data inconsistencies and missing values.
- Normalization: Formatting rules are applied to the dataset.
- Deduplication: Redundant data is excluded or removed.
- Verification: Unusable data is deleted and anomalies are reported.
- Sort: The data is sorted by type.
Some other transformation techniques include Derivation, Filtering, Splitting, Joining, Summarization, Aggregation, & Data Validation. Data is transformed to a usable format and stored in a denormalized form using one or more table models in Data Warehouse.
Load
This is the final part of our ETL process. This involves migrating the data to the final destination. It could be a data warehouse or database on-premise or on the cloud. This data can be refreshed automatically when new data is extracted and transformed. This neat and organized data is further used by business analysts for visualization and exploration, by data scientists for experimentation and prediction, or by other end users.
ETL Use cases
Every organization uses ETL to handle data, process it, and make it actionable- to be used by stakeholders, analysts, scientists, etc. We need to use ETL when we have to,
Migrate Data
With the advent of new and advanced technology, organizations are moving from legacy systems to newer ones. This calls for Data Migration. It involves transforming data into the newer format and migrating it to the destination.
Data Warehousing
A data warehouse is a denormalized database where all the extracted and transformed data is loaded into. This data repository is queried for numerous purposes.
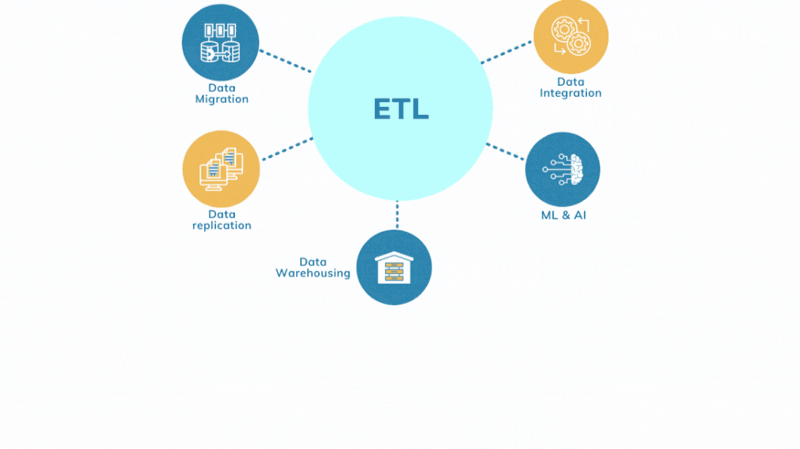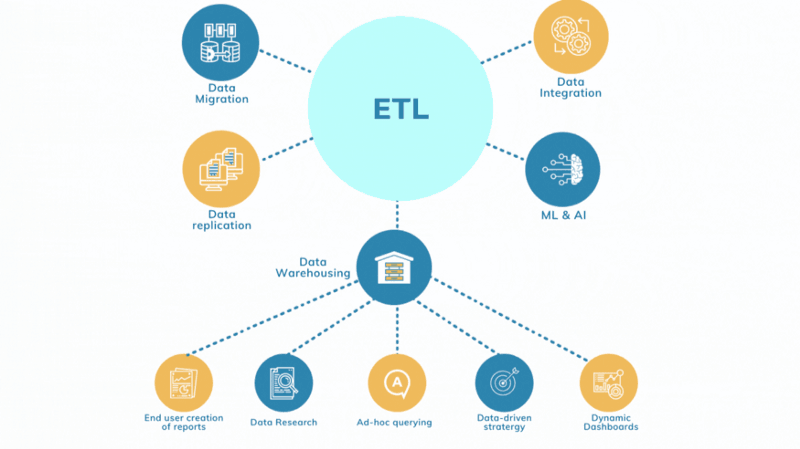
Data Integration
Be it for marketing or for IoT, ETL is used to collect data from social networks, web analytics, devices, sensors, etc., and all into one place for market analysis, IoT data integration, and other integrations.
Database Replication
Data is moved from source databases like Microsoft SQL Server, Cloud SQL for PostgreSQL, MongoDB, or others and copied into a data warehouse. ETL can be used to replicate the data for this one-time operation or an ongoing process.
Machine Learning and Artificial Intelligence
In the uber-important use case, System learns from the data using artificial intelligence techniques. Collected data can be used for machine learning purposes.
ELT vs ETL
Talking about ML, data scientists and analysts prefer to initially get all the data loaded and then based on the raw data, chalk out the transformation process of the data based on the requirement and research of the use case at hand. In short, first, the raw data would be extracted, loaded, and then transformed. This process is called Extract, Load, and Transform(ELT).

ETL requires running a transformation process before loading into the target system. With ELT, the target system is used as a place to run transformation processes. Complex use cases apply ELT where Data Lake is used as the repository to store a vast volume of raw data.
Whereas Data warehouse stores structured and filtered data, Data Lake stores unfiltered, heterogeneous data as is. ELT gives the flexibility to organizations to transform the raw data at any point of time, whenever and however necessary for a use case, and need not worry about transformation as a step in a data pipeline.
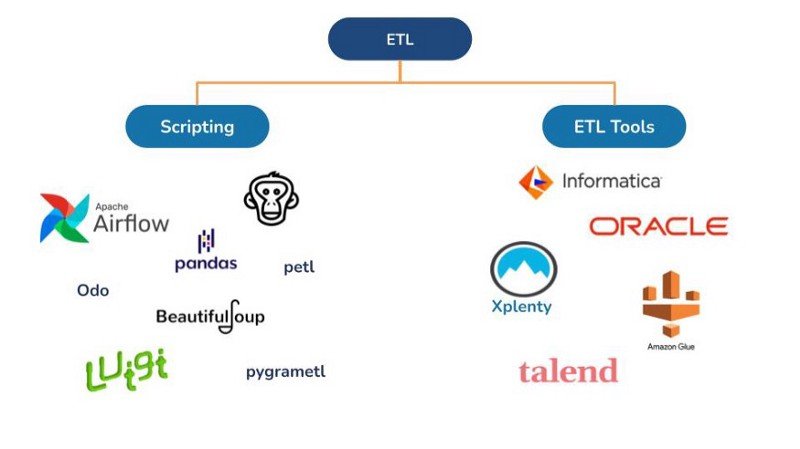
ETL Pipeline Tools
Data is the heart of an organization, and ETL plays a large role to keep it up and about. We are posed with two options for performing ETL. We can achieve the magic of ETL using two methods, One is scripting. i.e, building our own ETL tools from scratch using a programming language and the other is using already built ETL tools.
“Data is the new gold!” they say. Data is needed on-demand, easy and quick in its cleanest form. To facilitate this, more and more transformation techniques are being used today. Companies can gain insights, can derive decisions, and make impactful analyses using data only after the magical process of ETL!
Before using data to make beautiful employee dashboards, the HR team needs well-organized data, before a chef is graded; reviews, ratings, and comments are extracted, transformed, and loaded from a single source of truth, to get credit scores, data from all the transactions, loan history, payment is combined and analyzed.
If you like what we do and want to know more about our community 👥 then please consider sharing, following, and joining it. It is completely FREE.
Also, don’t forget to show your love ❤️ by clapping 👏 for this article and let us know your views 💬 in the comment.
Join here: https://blogs.colearninglounge.com/join-us