Database Normalization


Database Normalization, aka Normalization, in simple words, is the efficient Architecture of a database. Efficient Architecture is the Keyword here. It is a process of organizing your database in the most efficient form.
Normalization starts with understanding the data. Once you have understood your data, you implement a certain set of rules on it, and it is done.
In this article, you will understand the A to Z of Normalization. From What is Normalization? Why does the world even need it? How do you apply those certain sets of normal rules to get your Data in Normal Form?
As usual, We will use a real-life relatable story and examples to understand it from scratch.
Let’s get right into it!
First, let’s understand why it is important to Normalize your data.
Data Redundancy-
Data Redundancy, in simple words, is having unnecessary data stored in multiple places. That would be a waste of storage. Right? Or If we intend to delete data and lose useful data.
Let’s break it down with an easy example: suppose you have a store where you sell Playstations. While entering inventories in the computer, Mistakenly, you entered the same stock twice. Because of that, you end up overselling it, assuming you still have stock. Imagine how big of an impact on customer service would be because your customers will not wait for the refilling of the stock after realizing the mistake.
This happened because of Data Redundancy. This loss is from a business perspective.
From our data perspective, we consumed unnecessary storage and couldn’t make a better decision for the business because of data redundancy.
Problems caused by Data Redundancy are known as Anomaly, or an anomaly is an unexpected problem with the data which is not meant to be there.
There are three types- Insert Anomaly, Update Anomaly, and Delete Anomaly.
Let’s understand these problems first and how I came across these problems for the first time.
So, I got a task to work with a zoo, and I had to manage all data of animals as they were planning to expand, and the zoo was renamed Animal Farm. ))
So here is the raw table that was shared-

If a Database Administrator looks at it, they would be petrified, and so was I. I wouldn’t have chills after seeing the lion across as I had once seen this.
There are many problems with this, like duplicate data (Which takes up extra space) and irrelevant data (Which uses a lot of unrequired machine power while executing queries) also, it becomes more challenging to maintain data. Let’s understand this step by step!
If they had one more animal migrated to the zoo, and they haven’t hired someone to take care, this would look like this-

Here, we can not INSERT a new Animal because Zookeeper and Salary are empty until we have hired a new zookeeper. This would create issues while analyzing this data. This is called Insert Anomaly.
{Insert Anomaly is a kind of problem when we can’t ADD any data until we have other data points (like in this case, if we don’t have information like Feed1, Feed2, Age, Origin). }
Second, suppose the zoo authority decides to replace Fruits with ‘Leaves and vegetables.’ In that case, we have to check and replace it for all animals, which is quite a tedious task, and the chances of making an error are also high. This is called Update Anomaly.
{Update Anomaly is a kind of problem that data updates all across the table. The user ends up with data updated partially in some places only}.
There are many severe consequences of this. Suppose the zoo replaces veg with leaves because vegetable prices hiked up in a particular season. They will ask you to replace ‘veg’/’vegetable’ with Leaves. You wrote a correct SQL query to replace it, but because of Update Anomaly, all ‘Veg’ got replaced with Leaves, including the veg or non-veg in Feed2 of Lion.
Because of your wrong approach and unnormalized data, if say zookeeper took leaves for lunch for a Lion! Lion would make the zookeeper its lunch!
Third, suppose Amrish got a movie offer and decided to leave the zoo, and we have to delete Amrish from this table. We will not only lose Giraffe details but Grass, Seeds, etc. also. This is called Delete Anomaly.

{DELETE Anomaly IS A kind of problem WHEN DELETION HAPPENS FROM all across the table. The user ends up with EITHER LOOSING more than expected(like in this case) or keeps some of what was expected to be deleted}.
Now we know what issues arise if the database is not normalized or why the normalization of the database is essential.
“Normalization is a process to reduce data redundancy and improve data integrity.”
Now that we have understood it is essential to reduce data redundancy (by minimizing or eliminating anomalies) let’s explore this new term ‘Data Integrity.
To avoid all these issues, we do the effective architecture of the database by applying specific rules. This process is known as Database Normalization aka Normalization.
We will read about those rules and implement those parallely going further.
So For the zoo database, I had to do normalization on this because this is soo abnormal! 😂 Last one, I swear.


Each Normal Form is a set of steps to be applied to the database, which must be consistent. For example, if you are applying for Second Normal Form(2NF), you should have already applied for the First Normal Form(1NF). After the second form, you can apply for the Third Normal Form.
Let’s get right into it and apply these steps one by one!
First Normal Form (1NF) –
Normalization starts with 1NF. These are the first rules to be applied when you start the Normalization of your Database. Let me tell you how I did the Normalization of Animal Farm Data.
Here is what it looked like-

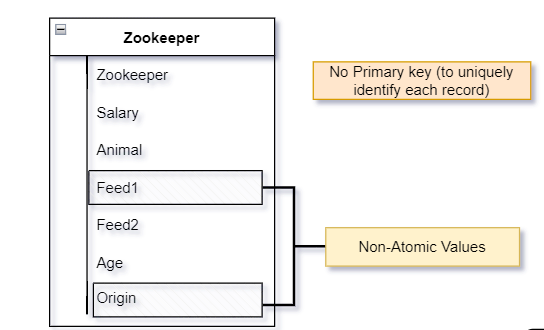
We can identify some problems from the first glimpse, e.g., several data is given in a single table(Zookeeper, Feed and Animal related details), repeating feed columns and inconsistent values like it are vegetable and veg for the same thing in different places.
To apply 1NF, you have to check two boxes mainly-
- Can each row be identified as a unique row?
- Each attribute has atomic values?
(An attribute is a column/field name! e.g., Zookeeper is an attribute, and Danny, Amrish, and Ranjit are its values.)
Now relating the first point to our data? Can each row be identified as unique?
Have a close look at the table! You can understand that two rows can be similar. E.g., suppose another deer migrated to the zoo, a twin to the same deer, and we add its details. The same zookeeper is assigned to take care of both. Now, Zookeeper, Salary, animal, age, and origin are the same in this transaction.

The answer is a big NO! Because for more extensive data, there can be many instances where two rows can be similar in the future. To check the first criteria, we have to put one column that identifies each row as unique, which can be Zookeeper_ID(Primary Key).
While we are at it, let me share another cool example to make this crystal clear- Suppose you create a social media account on Instagram or Facebook, and now there are sure chances that your attributes and values can be similar to any other person across the word (Name, Birthday, City and Country) so these platforms ask you to create a Username for your account. This username is the primary key for your details in their database as this is the unique value identifying your accounts.
For the second point, does each attribute have atomic values?
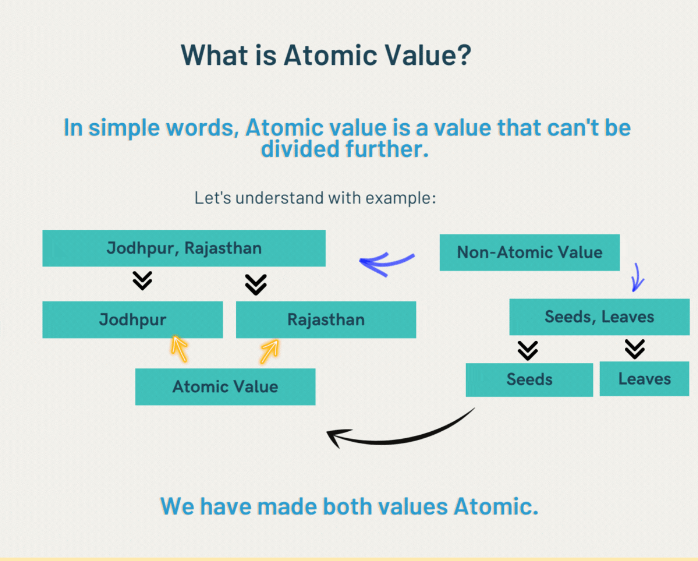
Can each attribute have atomic values?
No, but the origin and feed1 columns need to be.
So we have identified the problems-
This is ERD (Entity-relationship diagram). It is a common way to show data relations.
Let’s implement it on our data-

- To satisfy the first condition of 1NF, we have assigned a Zookeeper_ID, which uniquely identifies each row.
- And for the second condition, we have divided Feed(Feed_1, Feed_1(alt), Feed_2) and origin(origin_city, origin_country) to make all values atomic.
We have replaced irregular data here (like veg and vegetable are the same, so we have replaced veg to vegetable to make attributes consistent) This isn’t exactly part of 1NF, It is more of data pre-processing. The data that you normalize will be processed already, so this step won’t even be required to be done.
After implementing 1NF, here is what it looks like-
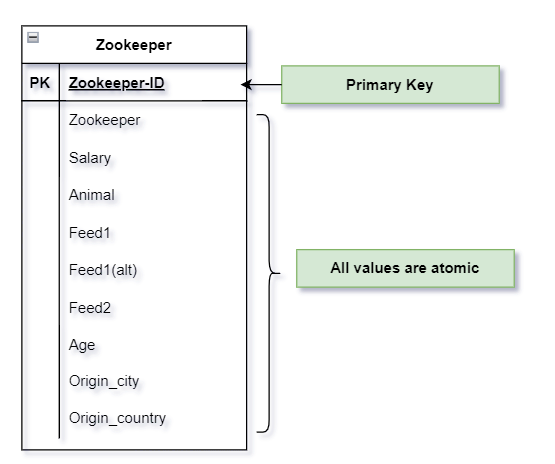
First Normal Form (1NF) Improvements-
Once the data is in its first normal form- it makes filtering, sorting, and searching easy.
The Primary key is added, so each record is uniquely identifiable. If one has to filter on a city or feed, because of all atomic values, it will also be easy.
Second Normal Form (2NF) –
To apply 2NF, you have to check two boxes mainly-
- You have applied 1NF.
- Each attribute should be dependent on the Primary key. This means each attribute in Row except the Primary key should be uniquely identified by Primary Key.
Let’s now compare these step by step with our Animal Farm Database.
First, we applied 1NF to our database. Our database is in its First normal form now, and this is how it looks-

Second, each attribute should be dependent on the Primary Key means the Primary Key should uniquely identify it.
In our table, Zookeeper_ID is the Primary key. Let’s check if each attribute-
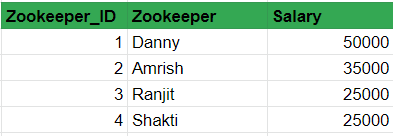
- Is Zookeeper dependent on Zookeeper_ID? Yes, because for every Zookeeper, there is this unique ID.
- Is salary dependent on Zookeeper_ID? Yes!
- Is Animal dependent on the Primary key? No, because a different zookeeper can handle multiple same-type of animals.
- Feed_primary? No, it is also not dependent on Zookeeper_ID! Feed_primary is related to Animals and can be repeated multiple times as most animals eat the same food.
- Feed_second? No, the same as Feed_primary; it is not dependent on the Primary key.
- Age? No, it is dependent on Animals on Not Zookeeper_ID.
- Origin_city– No! Because, again, it is dependent on Animal
- Origin_country– No! Same as Origin_city.
We have understood that only details specific to zookeepers depend on the Primary key. Once you do this, the task is almost done.
Let’s do some hands-on! How do we satisfy the second condition of 2NF?
We keep only the attributes that are dependent on the Primary key. And this is how it will be
ZooKeeper Table-
Animals Table-

If we look closely at both tables, we would understand that Zookeeper_Table is fine because all attributes depend on the Primary key, but Animal Table still has issues.
Let’s look at what is suspicious about it.
Now Let’s cross-check if this satisfies both rules of 2NF.
The first rule is to have 1NF implemented. Is it? Let’s check.
The first rule of 1NF says each row should be uniquely identified! Here can two rows have all values the same? The answer again is Yes. So we must add Animal_ID and make all rows/records uniquely identifiable.

The second rule of 1NF says all values should be atomic. Do you see any Non-atomic values? No, right.
So now we have this Animal table in First Normal Form because we have implemented 1NF rules.
As we have applied 2NF on the Zookeeper table already, before moving to 3NF, we need to apply 2NF for all tables in the database. So let’s apply 2NF on the Animal table and refresh our 2NF learnings.
There are two rules of 2NF-
- 1NF that should be already implemented (We have already implemented 1NF in the last step).
- Each attribute should be dependent on the Primary key. This means each attribute in Row except the Primary key should be uniquely identified by Primary Key.
Let’s check one by one-
- Is ‘Animal’ dependent on Animal_ID? Yes! Because it is assigned uniquely for each animal.
- Does Feed1 depend/uniquely identify with Animal_ID? No, Because there can be multiple animals with the same kind of Lunch. As you can see in our example, Deer and Chimp eat Fruit, so it is there in both, so obviously, Fruit can’t be determined uniquely by Primary Key.
- Does Feed2 depend on Animal_ID? No, same as Feed_primary.
- Age– Yes, it is! because it is specific to Animal_ID.
- Origin_city– Yes, because it is unique for each animal and can be identified with the primary key.
- Origin_country– Yes, same as Origin_city.
Feed_primary and Feed_second don’t follow the required rule, so let’s get these out of the Animal table.
Animals Table-

Feed Table-
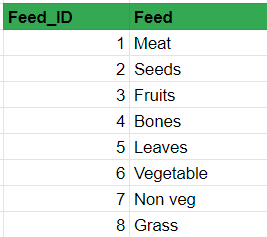
Please check for the Feed table if it satisfies all rules of 2NF(successful 1NF implementation & direct relation to primary key). It will be a good quick refresher!
And we have a total of three tables now in our Animal Farm Database. And at this point, you will realize how helpful ERD(Entity-Relationship Diagrams) are! Let’s have a quick look over our database-
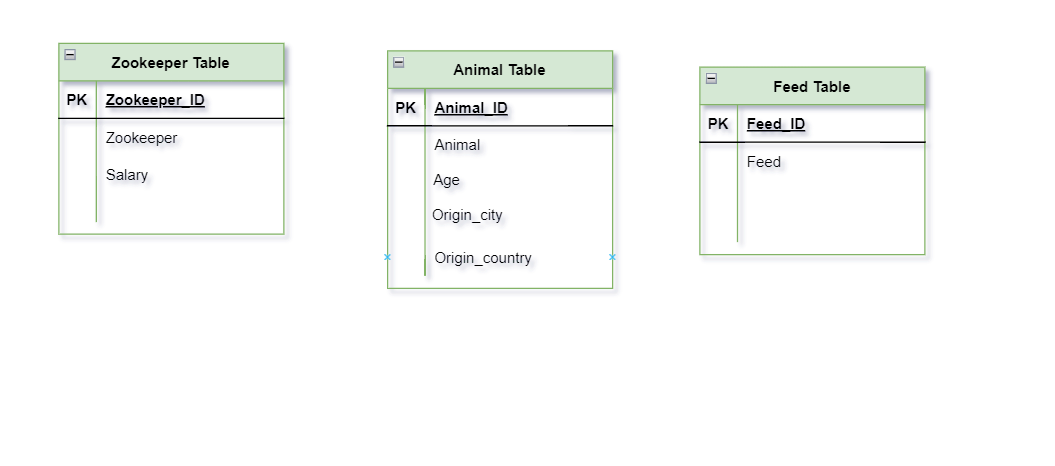
And now, our data is in Second Normal Form because 2NF is applied to it.
Second Normal Form (2NF) Improvements-
Once the data is in a second normal form, that means we have avoided the chances of all kinds of anomalies (Update, Insert and Delete).
It becomes easy to update different data points without worrying about Anomalies. So if we have to Update or delete or insert only specific data points because of different tables, we don’t have to worry about other details.
Third Normal Form (3NF) –
To apply the 3NF, there are simple rules-
- The table should be in the 2nd Normal Form (2NF is already applied)
- There shouldn’t be any Transitive Dependency.
Let’s first understand Transitive Dependency (TD)-
This is a classic statement that is widely used to explain TD “If A depends on B (A→ B) and B depends on C (B→ C), then A is transitively dependent on C (A→ C), and this TD should be removed in 3NF. That means only Direct dependency should be there. (It requires at least three attributes for this.)
One more example to understand: Suppose a table has three attributes (userID, Birthday, and Age). Now Age is dependent on Birthdays. Ofcourse as time passes, his age will increase, but the age stored on the table will stay the same. Also, data maintenance is effortful as we are entering the same kind of detail (depending) twice. This type of thing makes our data prone to error, which is why we remove the transitive dependency.
Let’s implement 3NF in our tables.
The first rule of 3NF is already satisfied as our tables are in the 2nd Normal Form.
We should check the 2nd rule now.
Let’s look at the tables again-
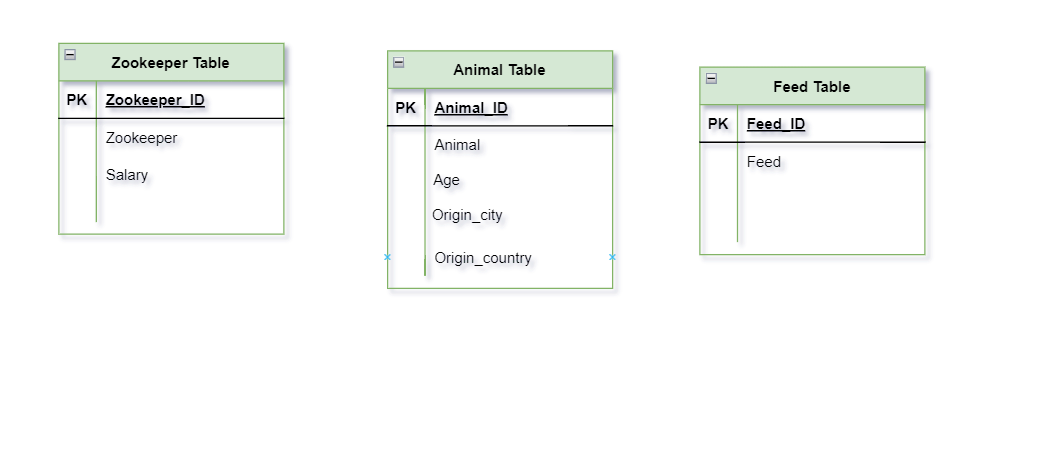
In the Zookeeper table, Zookeeper_ID is the primary key, and the Zookeeper name and Salary are directly dependent on Zookeeper_ID. That means this table doesn’t have any Transitive Dependency.
In the Feed table, there are only two attributes (Feed_ID and Feed), but at least three attributes are required for Transitive Dependency.
In the Animal table, Let’s check one by one-
- Animal Name is directly dependent on Animal ID.
- Age is also directly dependent on Animal ID.
- Origin_city is directly dependent on Animal_ID.
- Origin_country has Transitive Dependency. Because of Animal_ID → City and City→ Country. That means we should remove this Transitive dependency from our database in 3NF.
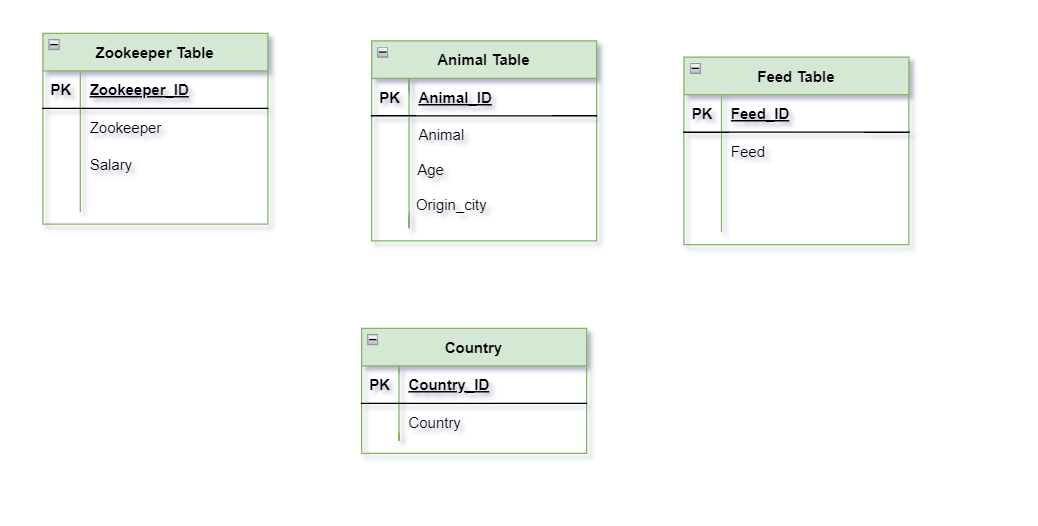
This Transitive Dependency is removed, and our data is in the 3rd Normal Form.
We have our Database in the Normalized form. These simple steps can be followed to improve our data’s integrity, leading to perfect decision-making.
Third Normal Form (3NF) Improvements-
After resolving transitive dependency, 3NF dramatically helps reduce data duplication and ensures functional dependency.
If you see the ERD above, there is only one step left before we use this data for our analysis: joining the tables with each other.
Let’s understand how to join the normalized data!
JOINING of the tables in the databases-
Now we have to join two tables.
This is what the normalized data looks like after joining-
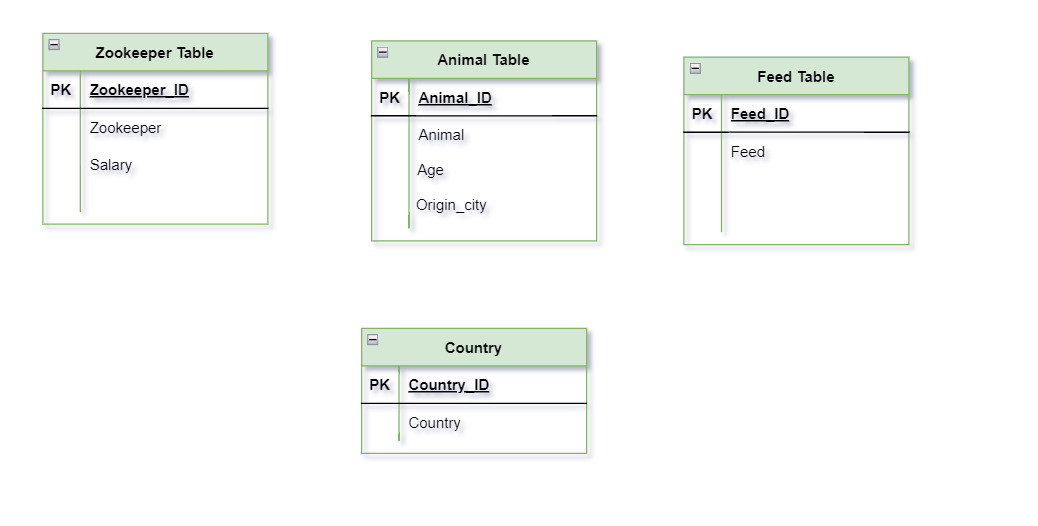
In SQL, Tables has to be related so that we can make sense of complete data together. Here we will add a additional table to connect (Based on Primary Key and Foreign Key) all tables to it so that final DB schema can be created.
New table that is added is, Zoocare Table
Task ID (Primary Key) – ID is to uniquely identify each task (Remember 1NF?)
Zookeeper_id (Foreign Key) – Zookeeper’s ID
Zookeeper Name – Zookeeper (wrt Zookeeper ID) who is responsible for that task
Animal_id (Foreign Key) – Animal who has to be taken care.
Database should be normalized till which step?
This is an excellent question in the field. The answer is very subjective. Data Normalization should be done as per the needs and type of analysis we are doing. If data in first normal form is sufficient to give the analysis and answers and it doesn’t impact your decisions in any way, then you don’t even need to process through the rest of the rules.
If the data can severely impact the accuracy of your analysis and hence the decisions, or it is impacting the performance of your machines, then you should have the data normalized in the most advanced forms. You can have this answer by analyzing your data and the type of analysis you would do daily.
Conclusion
In this article, we have understood how databases can be normalized and what kind of problems and anomalies can be roadblocks for us if the database is in an unnormalized form.
We also understood that it is done to avoid these anomalies, improve the performance of your queries, and achieve scalability.
No matter in the field, can tell you a one-word answer for ‘Data should be normalized to which step’? This entirely depends on our uses. There will be times when we have normalized data till the third normal form and realize that we need data from two tables simultaneously (it wasn’t a good idea to break both tables), and the third normal form has impacted performance negatively. In those cases, we denormalize the data. 🙂